JavaScript
 Edit on GitHub
Edit on GitHubjavascript 笔记
js的模块化
CJS,CommonJS
只能在 NodeJS 上运行,使用 require("module") 读取并加载模块。
缺点:不支持浏览器,执行后才能拿到依赖信息,由于用户可以动态 require(例如 react 根据开发和生产环境导出不同代码 的写法),无法做到提前分析依赖以及 Tree-Shaking 。
AMD,Asynchronous Module Definition
可以看作 CJS 的异步版本,制定了一套规则使模块可以被异步 require 进来并在回调函数里继续使用,然后 require.js 等前端库也可以利用这个规则加载代码了,目前已经是时代的眼泪了。
UMD,Universal Module Definition
同时兼容 CJS 和 AMD,并且支持直接在前端用 <script src="lib.umd.js"></script> 的方式加载。现在还在广泛使用,不过可以想象 ESM 和 IIFE 逐渐代替它。
代码案例
(function (root, factory) {if (typeof define === 'function' && define.amd) {// AMDdefine(['jquery'], factory);} else if (typeof exports === 'object') {// Node, CommonJS之类的module.exports = factory(require('jquery'));} else {// 浏览器全局变量(root 即 window)root.returnExports = factory(root.jQuery);}}(this, function ($) {// 方法function myFunc(){};// 暴露公共方法return myFunc;}));
如何在传统的 commonjs 项目中使用 es module的 模块
es module 如下 In your ES module file (test.js), you can use import and export syntax.
/utils/test.jsimport axios from 'axios';export function test() {console.log('test')}
step 1: Rename the File to .mjs
/utils/test.js ---> /utils/test.mjs
step 2: Dynamically Import the ES Module in CommonJS
app.post('/create-product', async (req, res) => {try {const { test } = await import('./utils/test.mjs'); // Dynamically import the ES module// you can use test() heretest();res.status(200).json({product:"aaa"});} catch (error) {console.error('Error creating product:', error);res.status(500).send('Failed to create product');}});
还有一种方法是 在 package.json 中加 "type": "module", 但这样会将所以js 文件当作 es module来处理,如果你要准备把你的commonjs 代码 都转换为 es 模块,你可以这样做
IIFE,Immediately Invoked Function Expression
只是一种写法,可以隐藏一些局部变量,前端人要是不懂这个可能学的是假前端。可以用来代替 UMD 作为纯粹给前端使用的写法
ESM, ECMAScript Module
现在使用的模块方案,使用 import export 来管理依赖。由于它们只能写在所有表达式外面,所以打包器可以轻易做到分析依赖以及 Tree-Shaking。当然他也支持动态加载(import())浏览器直接通过 <script type="module"> 即可使用该写法。NodeJS 可以通过使用 mjs 后缀或者在 package.json 添加 "type": "module" 来使用,注意他还有一些 实验性的功能 没有正式开启。考虑到大量 cjs 库没有支持,如果要发布 esm 版的库还是通过 rollup 打包一下比较好(同时相关依赖可以放到 devDependencies 里)。
Summary
- ESM is the best module format thanks to its simple syntax, async nature, and tree-shakeability.
- UMD works everywhere and usually used as a fallback in case ESM does not work
- CJS is synchronous and good for back end.
- AMD is asynchronous and good for front end.
ES6 模块特性 与 CommonJS 的区别
ES6 模块输出的是值的引用,输出接口动态绑定,而 CommonJS 输出的是值的拷贝
CommonJS 输出值的拷贝
// a.jsvar b = require('./b');console.log(b.foo);setTimeout(() => {console.log(b.foo);console.log(require('./b').foo);}, 1000);// b.jslet foo = 1;setTimeout(() => {foo = 2;}, 500);module.exports = {foo: foo,};// 执行:node a.js// 执行结果:// 1// 1// 1
ES6 输出值的引用
// a.jsimport { foo } from './b';console.log(foo);setTimeout(() => {console.log(foo);import('./b').then(({ foo }) => {console.log(foo);});}, 1000);// b.jsexport let foo = 1;setTimeout(() => {foo = 2;}, 500);// 执行:babel-node a.js// 执行结果:// 1// 2// 2
如何写一个js 库( module )?
其实很简单,要看你需要支持哪些平台:
只支持 NodeJS 的 require 写法
package.json:"main": "index.js",其中 index.js 使用 cjs 写法(module.exports = xxx;)
只支持 NodeJS 的 import 写法
package.json:"main": "index.mjs" 或 "type": "module", "main": "index.js"其中 index.mjs 或 index.js 使用 esm 写法(export default xxx)
同时支持 NodeJS 的 require 和 import 写法
利用 条件 export,直接看文档里面有例子。
使用import 或者 require 都可以的模块
// package.json"main": "./cjs/index.js","module": "./esm/index.js",In this package.json file, the "main" field specifies that the entry point for the CommonJS moduleIn this package.json file, the "module" field specifies that the entry point for the ESM module is;
nodejs 环境如何运行 es6 代码
1. 安装依赖(babel 7.x 以后的写法)$ npm i -g @babel/core @babel/node2. 安装 presets 并配置 .babelrc 文件npm i @babel/preset-env --save-dev.babelrc 文件配置内容:{"presets": ["@babel/preset-env"]}3. 执行 babel-node通过 babel-node 即可执行含有 import/export 等 es6 语法的 js 文件babel-node test.js
六种false
0NaN''nullundefinedfalseif(false){// do sth}
js数据类型有哪些?
值类型(基本类型):Data Types that are primitives, checked by typeof operator:undefined (未定义): typeof instance === "undefined"Boolean (布尔): typeof instance === "boolean"Number (数字): typeof instance === "number"String (字符串): typeof instance === "string"BigInt : typeof instance === "bigint" //es10新增Symbol : typeof instance === "symbol" //es6新增null : typeof instance === "object"引用数据类型:对象(Object)、数组(Array)、函数(Function)。注:Symbol 是 ES6 引入了一种新的原始数据类型,表示独一无二的值。
prototype
当试图得到一个对象的某个属性时,如果这个对象本身没有这个属性,那么会去他的 __prototype__ 即它的构造函数的prototype 中寻找// 构造函数function Foo(name, age) {this.name = name}Foo.prototype.alertName = function () {console.log(`alertName ${this.name}`)}// 创建实例var f = new Foo('zhangsan')f.printName = function () {console.log(`printName ${this.name}`)}f.printName()f.alertName()
堆(heap)和栈(stack)
堆 是堆内存的简称。栈 是栈内存的简称。说到堆栈,我们讲的就是内存的使用和分配了,没有寄存器的事,也没有硬盘的事。各种语言在处理堆栈的原理上都大同小异。javascript面向对象的语言本身在处理对象和非对象上就进行了划分,从数据结构的角度来讲,对象就是栈的指针和堆中的数值。
栈
栈是自动分配相对固定大小的内存空间,并由系统自动释放。线性结构,后进先出,便于管理javascript的基本类型就5种:Undefined、Null、Boolean、Number和String,它们都是直接按值存储在栈中的,每种类型的数据占用的内存空间的大小是确定的,并由系统自动分配和自动释放。这样带来的好处就是,内存可以及时得到回收,相对于堆来说,更加容易管理内存空间。
栈是只能在某一端插入和删除的特殊线性表。

堆
堆是动态分配内存,内存大小不一,也不会自动释放。一个混沌,杂乱无章,方便存储和开辟内存空间javascript中其他类型的数据被称为引用类型的数据 :如对象(Object)、数组(Array)、函数(Function) …,它们是通过拷贝和new出来的,这样的数据存储于堆中。其实,说存储于堆中,也不太准确,因为,引用类型的数据的地址指针是存储于栈中的,当我们想要访问引用类型的值的时候,需要先从栈中获得对象的地址指针,然后,在通过地址指针找到堆中的所需要的数据。
队列(Queue)
它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。队列的数据元素又称为队列元素。在队列中插入一个队列元素称为入队,从队列中删除一个队列元素称为出队。因为队列只允许在一端插入,在另一端删除,所以只有最早进入队列的元素才能最先从队列中删除,故队列又称为先进先出(FIFO—first in first out)

深拷贝与浅拷贝的区别及实现
深拷贝和浅拷贝的使用场景是在复杂对象里,即对象的属性还是对象,浅拷贝是指只复制一层对象,当对象的属性是引用类型时,实质复制的是其引用,当引用指向的值改变时也会跟着变化//浅拷贝var obj = { a:1, arr: [2,3] };var shallowObj = shallowCopy(obj);function shallowCopy(src) {var dst = {};for (var prop in src) {if (src.hasOwnProperty(prop)) {dst[prop] = src[prop];}}return dst;}//当一个对象属性的引用值改变时将导致另一个也改变shallowObj.arr[1] = 5;obj.arr[1] // = 5// 深拷贝1.通过递归实现function deepClone(o){if (Object.prototype.toString.call(o) === '[object Object]') {let n = {}for (let i in o) {n[i] = deepClone(o[i])}return n}else if(Object.prototype.toString.call(o) === '[object Array]'){let n = []for (let i = 0; i < o.length; i++) {n[i] = deepClone(o[i])}return n}else{return o}}2.通过JSON解析实现JSON.parse(JSON.stringify(o))Object.assign 是浅copylet obj_a={a:[1,2,3],b:"b",c:"c"}let obj_b=Object.assign({},obj_a)console.log(obj_b)// { a: [ 1, 2, 3 ], b: 'b', c: 'c' }obj_b.a[1]=999console.log(obj_b)// { a: [ 1, 999, 3 ], b: 'b', c: 'c' }console.log(obj_a)// { a: [ 1, 999, 3 ], b: 'b', c: 'c' }多说一句,Object.assign({}, src1, src2); 对于scr1和src2之间相同的属性是直接覆盖的,如果属性值为对象,是不会对对象之间的属性进行合并的let src1 = {'name': {a:2,c:"c"},'age': '20'};let src2 = {'name': {a:1,b:"b"},'age': '22'};let c = Object.assign({}, src1, src2)console.log(c);// { name: { a: 1, b: 'b' }, age: '22' }// 使用 map 解决循环引用问题function deepClone(obj, map = new Map()){if(typeof obj === "object"){let res = Array.isArray(obj) ? [] : {};if(map.get(obj)){return map.get(obj)}map.set(obj, res)for(let i in obj){res[i] = deepClone(obj[i], map)}return map.get(obj)}else{return obj}}var A = {a:1,b:[1,2,3]};A.B = A;var B = deepClone(A);console.log(B)
js 精度问题以及解决方案
0.1 + 0.2 === 0.30000000000000004 问题进制转换首先我们需要了解如何将十进制小数转为二进制,方法如下:对小数点以后的数乘以2,取结果的整数部分(不是1就是0),然后再用小数部分再乘以2,再取结果的整数部分……以此类推,直到小数部分为0或者位数已经够了就OK了。然后把取的整数部分按先后次序排列只能精确表示可用科学计数法 m*2^e 表示的数值而已比如0.5的科学计数法是2^(-1),则可被精确存储;而0.1、0.2则无法被精确存储能被转化为有限二进制小数的十进制小数的最后一位必然以 5 结尾(因为只有 0.5 * 2 才能变为整数)。所以十进制中一位小数 0.1 ~ 0.9 当中除了 0.5 之外的值在转化成二进制的过程中都丢失了精度。对这种无限循环的二进制数应该怎样存储呢,总不能随便取一个截断长度吧。这个时候IEEE754规范的作用就体现出来了。
js 垃圾回收机制
JavaScript 中的内存管理是自动执行的,而且是不可见的。可达性JavaScript 中内存管理的主要概念是可达性。简单地说,“可达性” 值就是那些以某种方式可访问或可用的值,它们被保证存储在内存中。问什么是垃圾?一般来说没有被引用的对象就是垃圾,就是要被清除, 有个例外如果几个对象引用形成一个环,互相引用,但根访问不到它们,这几个对象也是垃圾,也要被清除。
引起内存泄漏的情况
1.意外的全局变量引起的内存泄漏。function foo(arg) {bar = "this is a hidden global variable"; // 没有用var}function foo() {this.variable = "potential accidental global";}// 一般函数调用,this指向全局原因:全局变量,不会被回收。解决:使用严格模式避免,函数内使用var定义,块内使用let、const。2. 闭包引起的内存泄漏3.循环引用function problem() {var objA = new Object();var objB = new Object();objA.someOtherObject = objB;objB.anotherObject = objA;}
匿名函数和普通函数的区别
匿名函数:如 var a=function(){ return 1 };此函数function 没有函数名,但是它将值赋给了变量 a普通函数: function abc(){ return 1 };此函数声明了一个名为abc的函数。使用匿名函数表达式时,函数的调用语句,必须放在函数声明语句之后!普通函数在编译后函数声明和他的赋值都会被提前(包括: return 1 都会被提前)。所以普通函数的调用可以在任意位置。
用new操作符使用构造函数创建对象时发生的事情
第一步: 创建一个新对象Object。第二步: 新对象的__proto__属性指向构造函数的原型对象prototype,将构造函数的作用域赋值给新对象。(this对象指向新对象)第三步: 执行构造函数中的代码第四步: 返回新生成的对象实例//被调用的函数没有显式的 return 表达式(仅限于返回对象),则隐式的会返回 this 对象 - 也就是新创建的对象。原本的构造函数是window对象的方法,如果不用new操作符而直接调用,那么构造函数的执行对象就 是window,即this指向了window。现在用new操作符后,this就指向了新生成的对象。理解这一步至关重要构造函数的this指向创建的实例对象
js prototype
所有引用类型(数组、对象、函数),都有一个 __proto__ 属性,属性值是一个普通的对象__proto__ 为隐式原型__proto__ 属性值指向它的构造函数的 prototype (显示原型)属性值所有函数,都有一个 prototype 属性,属性值也是一个普通对象prototype 为显示原型function Mathhandle(){console.log(this)}typeof Mathhandle// "function"Mathhandle.prototype.constructor === Mathhandle// truelet m = new Mathhandle()m.__proto__ === Mathhandle.prototype// true

function Elem(id) {this.elem = document.getElementById(id)}Elem.prototype.html = function (val){var elem = this.elemif(val){elem.innerHTML = valreturn this // for 链式操作}else{return elem.innerHTML}}Elem.prototype.on = function (type,fn){var elem = this.elemelem.addEventListener(type,fn)return this}var div1 = new Elem('someID')//console.log(div1.html())div1.html(`<p>hello world</p>`).on("click",function(){console.log("clicked")})
instanceof
用于 引用类型 属于哪个 构造函数 的方法
instanceof 运算符用来测试一个对象在其原型链中是否存在一个构造函数的 prototype 属性
console.log([1] instanceof Array)//trueconsole.log([1] instanceof Object)//trueconsole.log({a:"a"} instanceof Array)//falseconsole.log({a:"a"} instanceof Object)//true
手写一个 instanceof
function myInstanceof(left, right){let prototype = Object.getPrototypeOf(left)while(true){console.log(`triggered while`)if(prototype === null) return falseif(prototype === right.prototype) return trueprototype = Object.getPrototypeOf(prototype)}}let a = myInstanceof ({}, Object)// true
fetch与ajax(XMLHttpRequest)相比
ES6中新增了一种HTTP数据请求的方式,就是fetchfetch更为简洁,而且fetch请求属于promise结构,直接.then()方法处理回调数据,当出错时,会执行catch方法,而且promise避免了回调金字塔的问题// fetchfetch(url).then(response => response.json()).then(data => console.log(data)).catch(e => console.log("Oops, error", e))// xhrvar xhr = new XMLHttpRequest();xhr.open('GET', url);xhr.responseType = 'json';xhr.onload = function() {console.log(xhr.response);};xhr.onerror = function() {console.log("Oops, error");};xhr.send();
axios 与 fetch
如何处理返回对象
Using fetch, the response object needs to be parsed to a JSON object:
fetch('/', {// configuration}).then(response => response.json()).then(response => {// do something with data})
Axios library returns a data object that has already been parsed to JSON
axios({url: '/',// configuration}).then(response => {// do something with JSON response data})
Axios’s library has a few other useful features
Interceptors: Access the request or response configuration (headers, data, etc) as they are outgoing or incoming. These functions can act as gateways to check configuration or add data.Instances: Create reusable instances with baseUrl, headers, and other configuration already set up.Defaults: Set default values for common headers (like Authorization) on outgoing requests. This can be useful if you are authenticating to a server on every request.
判断对象或者数组
//对象Object.prototype.toString.call(value)==='[object Object]'//数组Object.prototype.toString.call(value) === '[object Array]'
数组去重
let a = ["1", "1", "2", "3", "3", "1"];let unique = a.filter((item, i, ar) => ar.indexOf(item) === i);console.log(unique);使用setlet unique = [...new Set(a)]
Object.defineProperty()
The static method Object.defineProperty() defines a new property directly on an object, or modifies an existing property on an object, and returns the object.Object.defineProperty(o, 'a', {value: 37,writable: false, //defaultenumerable: false, //defaultconfigurable: false //default});//exampleconst foo = {name: "qianduan"}Object.defineProperty(foo, 'state',{value: 'static'})console.log(foo)//browser env{name: "qianduan", state: "static"}//nodejs env{ name: 'qianduan' }// If a property is non-enumerable, Node.js chooses not to display the property, that's it//but in nodejs, you can access the non-enumerable valueconsole.log(foo.state)// static// if add enumerable trueconst foo = {name: "qianduan"}Object.defineProperty(foo, 'state',{value: 'static',enumerable: true})console.log(foo)//{ name: 'qianduan', state: 'static' }//same result as browser env without enumerable: true
string method 字符串方法
将一个字符串按照某个长度分割,形成一个数组var str = "这是一个测试的字符串,它将被分割为多个元素,分割长度为5,最后一个元素为剩余的元素,可能不为5"str.match(/.{1,5}/g)判断是不是以什么结尾endsWith()"fdsafa".endsWith("fa")判断是不是以什么开头startsWith()"Hello world, welcome to the universe".startsWith("Hello")截取一段字符串substr(start, length)"Hello world!".substr(1, 4)// "ello""Hello world!".substr(2)// "llo world!"去掉末尾n位var str = '1437203995000';str = str.substring(0, str.length-3);// "1437203995"String slice()string.slice(start, end)var str = "Hello world!";var res = str.slice(3);//lo world!var str = "Hello world!";var res = str.slice(0,1);//H (不包含1)//负值,从末尾开始截取var str = "Hello world!";var res = str.slice(-1);//!//去掉末尾 n 位, 第二个值传 -nvar str = "Hello world!";var res = str.slice(0, -1);//Hello world (不包含1)String.prototype.startWith = function (str) {return typeof this.indexOf === 'function' && this.indexOf(str) === 0;};String.prototype.ismatch = function (regex) {return typeof this.match === 'function' && this.match(regex) !== null;};
数组方法
splice 删除某个元素
array.splice(index, howmany, item1, ....., itemX) index: 从第几位开始操作(0开始) howmay: 要删除的元素个数,如果要加,howmany 为0, item1,...itemX: 为要加进去的元素
var arr = [5, 15, 110, 210, 550];var index = arr.indexOf(210);if (index > -1) {arr.splice(index, 1);}
js array shift
Shift (remove) the first element of the array:
会改变原数组,返回值为shift(remove) 的值
a = [1, 2, 3, 4, 5, 6, 7]b = a.shift()b // 1a // [2, 3, 4, 5, 6, 7]
js array unshift
The unshift() method adds new elements to the beginning of an array.
const fruits = ["Banana", "Orange", "Apple", "Mango"];const c = fruits.unshift("Lemon","Pineapple");c // 6 返回值为新的数组的长度fruits // ['Lemon', 'Pineapple', 'Banana', 'Orange', 'Apple', 'Mango']
js array push
The push() method adds new items to the end of an array.
const fruits = ["Banana", "Orange", "Apple", "Mango"];const c = fruits.push("Kiwi");c // 5 返回值为新的数组的长度fruits // ['Banana', 'Orange', 'Apple', 'Mango', 'Kiwi']
js array pop
The pop() method removes (pops) the last element of an array.
const fruits = ["Banana", "Orange", "Apple", "Mango"];const c = fruits.pop();c //'Mango' 返回删除的那条数据fruits // ['Banana', 'Orange', 'Apple']
arr sort
array.sort(fun);参数fun可选。规定排序顺序。必须是函数。不传参数,将不会按照数值大小排序,按照字符编码的顺序进行排序;var arr2 = [30,10,111,35,1899,50,45];var resArr2 = arr2.sort();console.log(resArr2);//输出 [10, 111, 1899, 30, 35, 45, 50]按照值排序var arr=[11,45,2,32,89,0];arr.sort(function(a,b){return a-b;})console.log(arr);// 对数组里面的汉字排序// localeCompare()var arr = ["吃","安","的","不"]arr.sort((a,b)=>a.localeCompare(b,"zh"))console.log(arr)//["安", "不", "吃", "的"]//根据数组中的对象的某个属性值排序var arr5 = [{id:10},{id:5},{id:6},{id:9},{id:2},{id:3}];arr5.sort(function(a,b){return a.id - b.id})console.log(arr5);//多个属性排序var arr6 = [{id:10,age:2},{id:5,age:4},{id:6,age:10},{id:9,age:6},{id:2,age:8},{id:10,age:9}];arr6.sort(function(a,b){if(a.id === b.id){//如果id相同,按照age的降序return b.age - a.age}else{return a.id - b.id}})console.log(arr6);
arr.reverse()
//颠倒数组中元素的顺序var arr=[11,45,2,32,89,0];arr.reverse();console.log(arr);//[0, 89, 32, 2, 45, 11]
how does Array.prototype.slice.call() work?
function test(){let arr = Array.prototype.slice.call(arguments)// arguments 其实是一个对象,而不是数组}test(1, 2, 3, 4)slice 是数组的方法当我们执行[1,2,3].slice()时,the [1,2,3] Array is set as the value of [this] in .slice()The .call() and .apply() methods let you manually set the value of this in a function.So if we set the value of this in .slice() to an array-like object,.slice() will just assume it's working with an Array, and will do its thing.Take this plain object as an example.var my_object = {'0': 'zero','1': 'one','2': 'two','3': 'three','4': 'four',length: 5};This is obviously not an Array, but if you can set it as the this value of .slice(), then it will just work, because it looks enough like an Array for .slice() to work properly.var sliced = Array.prototype.slice.call( my_object, 3 );//['three','four'];Because arguments has a .length property and a bunch of numeric indices,.slice() just goes about its work as if it were working on a real Array.
柯里化
柯里化(Currying),又称部分求值(Partial Evaluation),是把接受多个参数的原函数变换成接受一个单一参数(原函数的第一个参数)的函数,并且返回一个新函数,新函数能够接受余下的参数,最后返回同原函数一样的结果。核心思想是把多参数传入的函数拆成单(或部分)参数函数,内部再返回调用下一个单(或部分)参数函数,依次处理剩余的参数。
柯里化有3个常见的作用
参数复用提前返回延迟计算/运算
柯里化的通用实现
//ES5 方式function currying(fn) {var rest1 = Array.prototype.slice.apply(arguments)rest1.shift()//除掉传入的第一个参数,也就是函数本身return function () {var rest2 = Array.prototype.slice.apply(arguments)return fn.apply(null, rest1.concat(rest2))}}//ES6 方式function currying(fn,...rest1) {return function (...rest2) {fn.apply(null,[...rest1, ...rest2])}}function sayHello(name, age, fruit) {console.log(`我叫 ${name},我 ${age} 岁了, 我喜欢吃 ${fruit}`)}let test = currying(sayHello,'xiaoming')test(25, "banana")let test2 = currying(sayHello,'xiaohong', 25)test2("apple")// 实现一个add方法,满足以下功能// add(1);//1// add(1)(2);//3// add(1,2);//3// add(1)(2)(3);//6// add(1,2)(3);//6// add(1,2,3);//6/**** @param {*要柯里化的函数} fn* @param {*调用柯里化方法所有柯里化参数总和} argNumber*/function curry(fn, argNumber) {let length = argNumberreturn function(...arg){console.log(`arg.length == ${arg.length}`)if(arg.length >= length){//最终执行时,会将以前bind的参数 和 最后一次传入的arg一起 传入return fn(...arg)}return curry(fn.bind(null, ...arg), length - arg.length)}}function oldAdd(...arg){return arg.reduce( (acc, currentValue) => {return acc + currentValue})}//对于 add(1)(2);//3let add = curry(oldAdd, 2);//一共两个参数对于// add(1)(2)(3);//6// add(1,2)(3);//6// add(1,2,3);//6let add = curry(oldAdd, 3);//一共三个参数
反柯里化
柯里化是固定部分参数,返回一个接受剩余参数的函数,也称为部分计算函数,目的是为了缩小适用范围,创建一个针对性更强的函数。核心思想是把多参数传入的函数拆成单参数(或部分)函数,内部再返回调用下一个单参数(或部分)函数,依次处理剩余的参数。而反柯里化,从字面讲,意义和用法跟函数柯里化相比正好相反,扩大适用范围,创建一个应用范围更广的函数。使本来只有特定对象才适用的方法,扩展到更多的对象。
反柯里化的通用实现
//ES5 方式Function.prototype.unCurrying = function() {var self = thisreturn function(){var rest = Array.prototype.slice.call(arguments)return Function.prototype.call.apply(self, rest)}}
柯里化和反柯里化的区别
柯里化是在运算前提前传参,可以传递多个参数;反柯里化是延迟传参,在运算时把原来已经固定的参数或者 this 上下文等当作参数延迟到未来传递。
偏函数
偏函数是创建一个调用另外一个部分(参数或变量已预制的函数)的函数,函数可以根据传入的参数来生成一个真正执行的函数。其本身不包括我们真正需要的逻辑代码,只是根据传入的参数返回其他的函数,返回的函数中才有真正的处理逻辑比如:var isType = function(type) {return function(obj) {return Object.prototype.toString.call(obj) === `[object ${type}]`}}var isString = isType("String")var isFunction = isType('Function')console.log(stringType("fsa"))这样就用偏函数快速创建了一组判断对象类型的方法~偏函数和柯里化的区别:柯里化是把一个接受 n 个参数的函数,由原本的一次性传递所有参数并执行变成了可以分多次接受参数再执行,例如:add = (x, y, z) => x + y + zcurryAdd = x => y => z => x + y + z偏函数固定了函数的某个部分,通过传入的参数或者方法返回一个新的函数来接受剩余的参数,数量可能是一个也可能是多个;当一个柯里化函数只接受两次参数时,比如 curry()(),这时的柯里化函数和偏函数概念类似,可以认为偏函数是柯里化函数的退化版。
递归 recursion
递归就是一个函数在函数内部调用自己,满足一定条件下停止调用
let countDownFrom = (num) => {if (num === 0) returnconsole.log(num)countDownFrom(num - 1)}countDownFrom(10)
小案例,树结构: 思路: 首层父节点可以找到 找到首层父节点的n个直接子节点 n个直接子节点重复上面找其直接子节点的动作,直到最下层没有子节点后结束
let categories = [{ id: 'animals', parent: null },{ id: 'mammals', parent: 'animals' },{ id: 'cats', parent: 'mammals' },{ id: 'dogs', parent: 'mammals' },{ id: 'chihuahua', parent: 'dogs' },{ id: 'labrador', parent: 'dogs' },{ id: 'persian', parent: 'cats' },{ id: 'siamese', parent: 'cats' }];function getTree(data, parent) {let outerObj = {}data.filter(i => i.parent === parent).forEach(i => outerObj[i.id] = getTree(data, i.id))if(Object.keys(outerObj).length === 0) return ''return outerObj}let res = getTree(categories, null)console.log(JSON.stringify(res, null, 2))//output// {// "animals": {// "mammals": {// "cats": {// "persian": "",// "siamese": ""// },// "dogs": {// "chihuahua": "",// "labrador": ""// }// }// }// }
给对象增加属性,不直接替换原对象
/**** 在原对象中增加属性,如果新对象和原对象的某个属性都是个对象,* 不直接替换,而是遍历新对象的属性,递归为原对象增加属性* @param {原对象} originalObject* @param {要将属性增加到原对象的对象} addObject*/export function addObjectAttr(originalObject, addObject) {if(!originalObject){originalObject = {}}for (let key of Object.keys(addObject)) {if(Object.prototype.toString.call(addObject[key])==='[object Object]'){originalObject[key] = addObjectAttr(originalObject[key], addObject[key])}else{originalObject[key] = addObject[key]}}return originalObject}
过滤树结构数据
function filterTree(node, keyword) {// Initialize an array to store filtered childrenconst filteredChildren = [];// Recursively filter childrenfor (const child of node.children) {const filteredChild = filterTree(child, keyword);if (filteredChild !== null) {filteredChildren.push(filteredChild);}}// Check if the current node's name contains the keywordconst nodeMatches = node.name.toLowerCase().includes(keyword.toLowerCase());// If the node matches or any of its children match, include the node with the filtered childrenif (nodeMatches || filteredChildren.length > 0) {return {id: node.id,name: node.name,children: filteredChildren};}// If neither the node nor its children match, return nullreturn null;}example data:const treeData = {id: "1",name: "Root",children: [{id: "1.1",name: "Branch 1",children: [{id: "1.1.1",name: "Leaf 1.1.1",children: []},{id: "1.1.2",name: "Leaf 1.1.2",children: []}]},{id: "1.2",name: "Branch 2",children: [{id: "1.2.1",name: "Branch 2.1",children: [{id: "1.2.1.1",name: "Leaf 1.2.1.1",children: []},{id: "1.2.1.2",name: "Leaf 1.2.1.2",children: []}]},{id: "1.2.2",name: "Leaf 1.2.2",children: []},{id: "1.9.2",name: "Leaf 1.9.2",children: []}]},{id: "1.3",name: "Branch 3",children: [{id: "1.3.1",name: "Branch 3.1",children: [{id: "1.3.1.1",name: "Leaf 1.3.1.1",children: []}]} ,{id: "1.2.600",name: "Leaf 1.2.600",children: []}]}]};const keyword = "1.2";const filteredTree = filterTree(treeData, keyword);
二叉树
防抖和节流 debounce and throttle
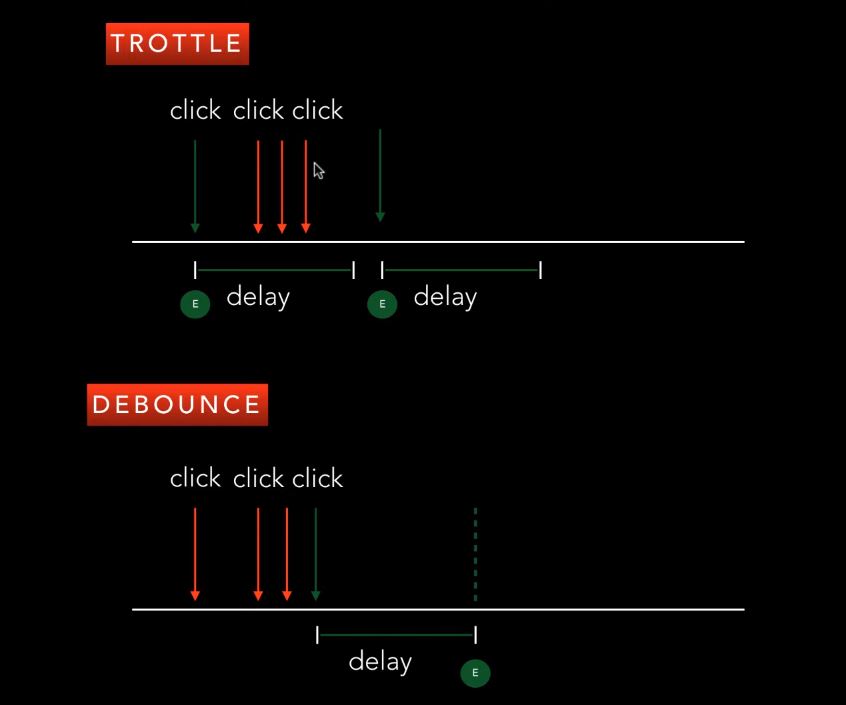
防抖debounce
在事件被触发n秒后再执行回调,如果在这n秒内又被触发,则重新计时。
Debouncing is a technique used to control and limit the frequency of a function's execution. It is particularly useful in scenarios where a function is triggered by an event that can fire multiple times in a short period, such as scrolling, resizing, or typing.
debounce can help optimize performance and prevent excessive function calls.
//在一定时间内,触发多次事件,只认最后一次触发的并且重置时间,到了时间结束执行事件//每次新的事件来了,就会清空老的计时器,让新的timer重新开始倒计时后执行对应的方法function debounce (fn, time){let timer = nullreturn function(){if(timer){clearTimeout(timer)}timer = setTimeout(() => {fn.call(this, ...arguments)},time)}}
// 有一个问题是,如果你一直不间断的触发,那就一次也不会执行
节流 throttle
In JavaScript, throttling is a technique used to control the rate at which a function is executed. It limits the number of times a function can be called within a specified time interval. Throttling helps to optimize performance and prevent excessive function invocations, particularly in scenarios where a function might be called frequently, such as when handling scroll events or user input.
function throttle (fn, time){let lastTime = 0;return function(){let nowTime = (new Date()).getTime()if(nowTime - lastTime > time){fn.call(this, ...arguments)lastTime = nowTime}}}
区别:
防抖
防抖的首次点击要等一定时间间隔后执行,如果还没有到一定的时间间隔又有新的点击,则首次(或者上次)点击失效,以最后一次点击重新计时
防抖的应用场景 搜索引擎 输入内容后调接口搜索内容,只有我连续不断输入(查询)内容结束后才调接口
节流
节流的首次点击立即有效,并记录此时为执行时间,后面一定时间间隔内的点击没用,等到一定时间间隔后的点击立即有效执行,并刷新此时为执行时间,然后一定时间间隔内的点击又没有效。。。
节流的应用场景 将一些事件降低触发频率。比如懒加载时要监听计算滚动条的位置,但不必每次滑动都触发,可以降低计算的频率
set
The Set object lets you store unique values of any type, whether primitive values or object references
Set objects are collections of values. You can iterate through the elements of a set in insertion order. A value in the Set may only occur once; it is unique in the Set's collection. Set 内部的成员是不允许重复的。那也就是说,每一个值在同一个 Set 当中是唯一的
基本用法 Using the Set object
let mySet = new Set()mySet.add(1) // Set [ 1 ]mySet.add(5) // Set [ 1, 5 ]mySet.add(5) // Set [ 1, 5 ]mySet.add('some text') // Set [ 1, 5, 'some text' ]let o = {a: 1, b: 2}mySet.add(o)mySet.add({a: 1, b: 2}) // o is referencing a different object, so this is okaymySet.has(1) // truemySet.has(3) // false, since 3 has not been added to the setmySet.has(5) // truemySet.has(Math.sqrt(25)) // truemySet.has('Some Text'.toLowerCase()) // truemySet.has(o) // truemySet.size // 5mySet.delete(5) // removes 5 from the setmySet.has(5) // false, 5 has been removedmySet.size // 4, since we just removed one valueconsole.log(mySet)// logs Set(4) [ 1, "some text", {…}, {…} ] in Firefox// logs Set(4) { 1, "some text", {…}, {…} } in Chrome
Iterating Sets
for (let item of mySet) console.log(item)
convert Set object to an Array object, with Array.from
let myArr = Array.from(mySet) // [1, "some text", {"a": 1, "b": 2}, {"a": 1, "b": 2}]
Relation with Array objects
let myArray = ['value1', 'value2', 'value3']// Use the regular Set constructor to transform an Array into a Setlet mySet = new Set(myArray)mySet.has('value1') // returns true// Use the spread operator to transform a set into an Array.console.log([...mySet]) // Will show you exactly the same Array as myArray
Remove duplicate elements from the array
const numbers = [2,3,4,4,2,3,3,4,4,5,5,6,6,7,5,32,3,4,5]console.log([...new Set(numbers)])// [2, 3, 4, 5, 6, 7, 32]
map
The Map object holds key-value pairs and remembers the original insertion order of the keys. Any value (both objects and primitive values) may be used as either a key or a value.
Map 集合与对象最大的区别就在于 Map 集合允许使用任意类型的数据作为键,而对象只能使用字符串作为键。
常用方法
let myMap = new Map()let keyString = 'a string'let keyObj = {}let keyFunc = function() {}// setting the valuesmyMap.set(keyString, "value associated with 'a string'")myMap.set(keyObj, 'value associated with keyObj')myMap.set(keyFunc, 'value associated with keyFunc')myMap.size // 3// getting the valuesmyMap.get(keyString) // "value associated with 'a string'"myMap.get(keyObj) // "value associated with keyObj"myMap.get(keyFunc) // "value associated with keyFunc"myMap.get('a string') // "value associated with 'a string'"// because keyString === 'a string'myMap.get({}) // undefined, because keyObj !== {}myMap.get(function() {}) // undefined, because keyFunc !== function () {}
Iterating Map with for..of
let myMap = new Map()myMap.set(0, 'zero')myMap.set(1, 'one')for (let [key, value] of myMap) {console.log(key + ' = ' + value)}// 0 = zero// 1 = onefor (let key of myMap.keys()) {console.log(key)}// 0// 1for (let value of myMap.values()) {console.log(value)}// zero// onefor (let [key, value] of myMap.entries()) {console.log(key + ' = ' + value)}// 0 = zero// 1 = onemyMap.forEach(function(value, key) {console.log(key + ' = ' + value)})// 0 = zero// 1 = one
Relation with Array objects
let kvArray = [['key1', 'value1'], ['key2', 'value2']]// Use the regular Map constructor to transform a 2D key-value Array into a maplet myMap = new Map(kvArray)myMap.get('key1') // returns "value1"// Use Array.from() to transform a map into a 2D key-value Arrayconsole.log(Array.from(myMap)) // Will show you exactly the same Array as kvArray// A succinct way to do the same, using the spread syntaxconsole.log([...myMap])// Or use the keys() or values() iterators, and convert them to an arrayconsole.log(Array.from(myMap.keys())) // ["key1", "key2"]
Cloning and merging Maps
let original = new Map([[1, 'one']])let clone = new Map(original)console.log(clone.get(1)) // oneconsole.log(original === clone) // false (useful for shallow comparison)let first = new Map([[1, 'one'],[2, 'two'],[3, 'three'],])let second = new Map([[1, 'uno'],[2, 'dos']])// Merge two maps. The last repeated key wins.// Spread operator essentially converts a Map to an Arraylet merged = new Map([...first, ...second])console.log(merged.get(1)) // unoconsole.log(merged.get(2)) // dosconsole.log(merged.get(3)) // three
异或运算 ^ XOR (exclusive OR)
运算符主要是在位运算的时候使用,但是在普通的数也能使用,且有一个转换过程,即将二进制的数转换为十进制
var a = 1 ^ 2;//3流程:转为为二进制//1 -> 01//2 -> 10二进制异或结果(11),再转变为十进制//1 ^ 2 -> 11 -> 3两个相同的数异或结果为05 ^ 5//06 ^ 6//00 ^ 0//0任何数异或0,结果为其本身4 ^ 0//4
DOM 事件
基本概念
DOM 事件的级别
DOM 0:element.onclick = function(){}<h1 id="h1a" onclick="trigger()">hello world triggered from html</h1>DOM 2:elementb.addEventListener("click", function(){console.log(`dom 2 event triggered`)}, false)DOM 3: 增加了 keyup 等键盘鼠标事件elementc.addEventListener("keyup", function(){console.log(`dom 3 (keyup)event triggered`)}, false)注意addEventListener 第三个参数:isCapture 是否在捕获阶段执行回调。默认为false,表示在冒泡阶段执行回调
DOM 事件模型
指事件捕获、事件冒泡
DOM 事件流
事件通过捕获到达目标阶段(捕获),目标元素在上传到window对象(冒泡)的过程
描述DOM 事件捕获的具体流程
常见 DOM 操作
// 通过id获取元素let element = document.getElementById("cssSelectors");// 通过选择器 获取匹配的第一个匹配元素let element = baseElement.querySelector(cssSelectors);// 通过选择器 获取匹配的所有元素let elements = document.querySelectorAll("cssSelectors");// 元素的显示和隐藏element.style.display="block"element.style.display="none"// 获取元素属性值let attribute = element.getAttribute(attributeName);eg:const align = div1.getAttribute('align')// 增加和删除元素classelement.classList.add("w3-black");element.classList.remove("w3-black");
Event 对象的常见应用
Event.preventDefault()Event.stopPropagation()Event.stopImmediatePropagation()//同一个元素绑定了很多监听事件,如果在某一个里面使用了stopImmediatePropagation,它后面的事件就不会执行了Event.currentTargetcurrentTarget is the element that the event listener is attached to.Event.targettarget is the element that triggered the event (e.g., the user clicked on)
自定义事件
let eve = new Event("test")elementc.addEventListener("test", function(){console.log(`custom event triggered`)})elementc.dispatchEvent(eve)
前端安全 XSS XSRF/CSRF
xss 跨站脚本攻击Cross-site scriptingXSS enables attackers to inject client-side scripts into web pages viewed by other users方法:转义<> 等特殊字符XSRF 跨站请求伪造Cross-site request forgery, also known as one-click attack or session riding and abbreviated as CSRF or XSRF, is a type of malicious exploit of a website where unauthorized commands are transmitted from a user that the web application trusts.方法:http referer 验证Token 验证, 在请求地址中添加 token 并验证在 HTTP 头中自定义属性并验证。增加验证流程,短信、密码、指纹等